권찬영 교수
동의대학교 한의과대학 한방신경정신과
필자는 이번 2024년 9월 10일부터 13일까지 체코 프라하에서 개최된 Global Evidence Summit 2024에 참석하였다. 이 국제학술대회는 ‘Using evidence. Improving lives’라는 슬로건으로, 전세계적으로 근거기반 의사결정을 촉진하고, 실질적인 건강 및 사회적 과제를 해결하기 위한 신뢰할 수 있는 연구 근거의 사용을 확대하기 위한 목적으로 개최되었으며, 파트너 조직으로는 Cochrane Collaboration, JBI, Guidelines International Network, Campbell Collaboration 등 evidence-based medicine 분야 주요 조직들이 함께 했다. 즉, 전세계의 연구자, 임상의, 정책 입안자들이 모여 최신 연구 방법론과 근거 합성 기술에 대해 논의하는 자리였다고 할 수 있다.
워낙 크게 개최된 학술대회이기도 하고, 같은 시간에도 여러 개의 세션이 열리기 때문에 모든 발표를 들을 수는 없었지만, 이번 학술대회 참여하고 기억에 남는 발표들과 생각을 이 참관기에 정리해보고자 한다.
AI와 의료연구의 미래
먼저, 인공지능(AI)과 머신러닝 기술을 활용한 자동화 도구들이 역시 큰 주목을 받았다. 첫날에 University of Santo Tomas의 Valentin C. Dones III 교수가 진행한 ‘Systematic Review Meets AI: A Modern Review Technique’라는 워크숍이 있었고, 체계적 문헌고찰을 수행하는 다양한 무료 AI 도구를 소개하고, 실제 실습을 진행했는데, 아쉽게 자리가 꽉 차서 들어가지 못했을 정도다. 그만큼 이번 학회에서 AI를 활용한 연구들의 소개가 인기였다. 첫 실패(?)를 경험하고, 그 다음 관심 주제부터는 미리 가서 자리를 맡아놓아야 겠다는 생각을 했다.
기억에 남는 발표들은 다음과 같다. Lanzhou 대학의 Xufei Luo (PhD 학생)는 의학 연구에서 챗봇 사용을 보고하기 위한 가이드라인인 CHEER (Reporting items for the use Chatbots and other similar cHatbots used in mEdical Research) statement 개발에 대해 발표했다. 이 가이드라인은 의학 연구자들이 논문 작성 시 챗봇 사용을 공개하고 보고하는 데 도움을 주기 위해 개발되었다고 한다. 역시 생성형 AI 사용은 의학연구 분야에 큰 영향을 미치고 있다. 그것은 기회가 되기도 하지만, 때로는 연구의 품질과 신뢰성에 위협이 되기도 하기 때문에, 연구의 수행과 보고에 있어서 체계적인 보고지침이 필요한 상황에서, 개발된 따끈따끈한 (아직 논문으로 출판되지 않은) 지침을 접할 수 있었다.
La Trobe 대학의 Hanan Khalil 교수의 발표는 오늘날 문헌고찰 방법론에서 사용되고 있는 AI 관련 자동화 도구들의 현황을 보여준다. 그녀는 현재까지 약 60편의 연구에서 70가지의 자동화 도구들이 다뤄졌다고 보고했는데, 각 문헌고찰 단계에 있어서 자동화된 기술의 성숙도와 과제를 다음과 같이 설명했다. (1)초록 스크리닝 단계에는 성숙기에 도달, (2)데이터 추출은 여전히 연구가 필요한 단계, (3)전문적으로 유지 관리되는 플랫폼의 개발이 필요, (4)연구의 품질 향상을 위한 과제도 남아있음, (5)이 도구의 테스트 및 검증을 위한 오픈 액세스 데이터셋을 만드는 작업이 필요함.
비슷한 내용을 브라질에서 온 의대생 팀이 발표하기도 했는데, 체계적 문헌고찰 수행을 위한 다양한 AI 도구들을 조사한 결과, 아직까지 체계적 문헌고찰의 과정을 완전히 대체할 수 있는 도구는 개발되지 않았으며, 특히 메타분석 수행 기능을 포함하는 상용화된 도구가 없다는 것을 지적했다. 또, 이러한 도구들의 사용으로 인해 발생할 수 있는 가장 큰 과제는 AI로부터 생성된 결과물의 품질을 평가하는 것이라고 설명했는데, 크게 공감이 갔다.
이후 TU Wien의 Wojciech Kusa 박사 연구가 흥미로웠는데, 이는 앞선 발표에서 소개한 것처럼, 현재까지 체계적 문헌고찰에서 AI의 사용은 주로 연구의 선별이나 질 평가 영역에 그치고 있었는 상황에서, Kusa 박사는 메타분석에서 머신러닝의 활용 가능성을 보고했기 때문이다. 구체적으로, 그는 일부 연구가 누락되더라도 머신러닝을 사용한 메타분석을 통해 정확한 결과 예측이 가능한지에 대해 시도했다고 한다.
이렇게 도전적인 연구자들 뿐 아니라, 실제적으로 AI를 사용하는 연구자들도 있었다. Bristol 대학의 Zhaozhen Xu 박사는 대규모 언어 모델(LLM)을 사용하여 체계적 문헌고찰을 위한 연구 스크리닝을 자동화하는 방법에 대해 발표했다. 특히, 그녀가 속한 그룹에서는 2007년부터 암에 대한 정보와 관련하여 최신의 체계적 문헌고찰을 서비스로 제공하고 있는데, 이번에 LLM을 적용하여 체계적 문헌고찰에 포함될 원 연구들을 반자동화하여 선별하는 과정을 공유한 것이다.
그렇다면 이러한 AI의 사용이 체계적 문헌고찰 과정에서 얼마나 이득이 될 것인가? Lanzhou 대학의 Jie Zhang은 LLM을 사용하여 문헌 스크리닝을 자동화한 연구 결과를 발표했고, GPT-3.5, GPT-4, Gemini, ERNIE Bot, GLM-10B-Chinese 등 다양한 LLM을 사용했다. 그리고 체계적 문헌고찰 과정 중 제목과 초록 스크리닝 과정을 자동화한 결과, 평균적으로 인간의 노동을 88.21% 경감시킬 수 있었다는 흥미로운 결과를 얻었다.
위에서 살펴본 이러한 연구들은 AI와 머신러닝 기술이 체계적 문헌고찰과 메타분석 과정을 획기적으로 개선할 수 있는 잠재력을 가지고 있음을 보여준다. 그러나 많은 발표자들이 지적했던 것처럼, 이러한 도구들의 정확성과 신뢰성을 지속적으로 평가하고 개선해야 할 필요성도 강조되고 있다. 그런 의미에서 CHEER statement와 같은 보고지침이 앞으로 더 보편적으로 사용되지 않을까 생각된다.

CPG 개발, AI로 효율성 극대화
임상진료지침(CPG) 개발에서의 혁신도 이번 학회의 큰 주제 중 하나였다. 한의계에서도 한의표준임상진료지침의 중요성이 강조되고 있는 상황에서, 임상진료지침 개발 방법론의 변화는 한의표준임상진료지침의 개발에도 큰 영향을 미칠 것이기에 더 흥미롭게 들었다.
먼저 소개할 발표는 HRB-CICER의 Barrie Tyner 박사의 가이드라인 개발의 주요 혁신에 대한 scoping review 결과이다. 2015년 이후 CPG 개발 및 도입에 있어서의 주요 변화를 조사한 결과, 다음과 같은 6가지 혁신으로 요약할 수 있었다고 한다. (1)인용 검색에 대한 자동화된 접근법, (2)진료지침 업데이트를 위한 실용적 검색전략의 개발, (3)근거/진료지침의 번역 (예: 환자 버전의 진료지침), (4)동반 질환이 있는 환자를 위한 여러 진료지침들의 통합 작업, (5)임상 정책, 절차, 프로토콜, 진료지침을 위한 표준화된 전자 템플릿, (6)체계적 문헌고찰에서 논문 스크리닝을 위한 머신러닝 접근법.
여기서도 역시 자동화된 접근법이나 머신러닝 접근법과 같은 AI의 사용이 중요한 혁신임을 알 수 있다. 이 외에도 CPG 개발 방법론의 개선이나 환자 중심 문서의 개발 등도 눈에 띈다. 이와 같은 임상진료지침 개발 방법론의 국제적인 흐름은 결국 한의계에도 반영될 것이다.
Oregon Health & Science 대학의 Susan Norri 교수의 발표도 기억에 남는다. 그녀는 기존 GRADE 방법론에서 사용하던 Good Practice Statements의 한계점을 지적했는데, 여기서 Good Practice Statements는 일반적인 GRADE 방법론에 따른 근거수준 평가나 권고강도 결정 과정을 거치지 않고, 주로 전문가 합의와 상식에 기반해서 만들어지는 진술이다. 참고로, 한의표준임상진료지침에서는 Good Practice Points라는 용어를 사용하며 개발그룹의 임상적 경험에 근거한 권고를 의미한다.
Norri 교수는 GRADE에서 사용하는 Good Practice Statements의 개념적 및 방법론적 문제를 지적하며, 결국 이 Statements를 사용하는 사람들이 이를 해석하고 도입하는데 있어서 불명확성을 초래한다며, 기존 Good Practice Statements을 포함하는 이러한 normative statements를 크게 경험적 근거에 기반한 normative statements와 인권, 윤리, 규범에 기반한 normative statements로 구분하는 분류체계를 사용해야 한다고 주장했다.
기존에 출판된 임상진료지침의 평가에 관한 발표도 있었다. 주로 AI를 활용하여 임상진료지침의 질을 평가한 결과였는데, Lanzhou 대학의 Bingyi Wang 박사가 발표한 이 발표에서는 AGREE II 도구를 사용한 대규모 언어 모델의 임상진료지침 평가에 대한 비교 분석 결과를 발표했다. 이 연구는 GPT-4와 같은 생성형 AI를 사용하여 CPG의 품질을 평가하는 시도였다. 15개의 CPG를 대상으로 한 평가 결과, AI는 평균 177초 만에 그 품질 평가를 완료했으며, 이는 신속성 면에서 큰 장점을 보여주었다.
하지만 AGREE II 도구의 일부 도메인에서는 AI의 평가가 잘 이루어지지 않는 경우도 확인되었다. 이 발표를 들은 청중 중 한 명이 AI의 평가가 잘 이루어지지 않은 도메인에 대해서, 그 이유를 어떻게 생각하는지 발표자에게 물었는데, 해당 영역이 다양한 사회적 및 문화적 관점이 포함되는 임상진료지침 내용에 대한 평가이기 때문으로 보이나, 아직까지 분명한 원인은 잘 모르겠다고 답했다.
이처럼 AI를 사용한 연구 방법론은 임상진료지침의 개발과 평가 과정에 새로운 방법론으로 도입됨으로써, 더 객관적이고 효율적인 가이드라인 개발이 가능해질 수 있으리라 생각된다. 그러나 동시에 이러한 새로운 접근법들의 타당성과 실효성에 대한 지속적인 검증이 필요하다는 점도 강조되고 있는 상황이다.

연구 신뢰성 평가의 새로운 도구들
기억에 남는 다른 발표는 연구방법론의 혁신이라고 명명할 수 있을 듯 하다. Monash 대학의 Simon Turner 박사는 기존 메타분석에서 통상적으로 만들어지는 forest plot과 달리, 모든 포함된 연구결과를 표시하기 위한 forest plot에 대해 발표했다. 기존의 forest plot은 메타분석에 포함된 연구 결과만을 표시했지만, Turner 박사는 정형화된 데이터가 없거나 결측치가 있는 연구 결과도 포함시키는 방법을 제안한 것이다. 아직은 상용화되지 않고, Turner 박사의 연구팀 내에서만 논의하고 있다고 하나, 곧 논문과 같은 문서를 통해 공개될 결과물이 기대된다.
INSPECT-SR라는 도구를 실습하는 워크샵도 참여했다. 이 도구는 INveStigating ProblEmatic Clinical Trials in Systematic Reviews의 약어인데, 체계적 문헌고찰을 수행함에 있어서 포함되는 RCT의 신뢰성을 평가하기 위해 현재 개발 중인 도구이다.
전문가 설문조사 – 적용가능성 및 영향 평가 – 델파이 조사 – 합의 – 사전 테스트 등의 과정을 거치며 개발 중인 이 도구는, 이번 워크샵에서도 사용자 패드백을 얻기 위해 참가자들이 실제로 이 도구를 사용해보도록 한 것이다.
이 도구는 기존 Cochrane의 RoB tool과 유사해보일 수 있는데, 사실 그 목적이 다르다. RoB tool은 연구 설계나 수행에서 발생할 수 있는 비뚤림 위험을 평가하는 것이라면, INSPECT-SR은 연구의 신뢰성, 특히 데이터의 진실성을 평가하여, 위조되거나 거짓된 데이터가 포함된 연구를 발견해내는 것에 초점을 맞춘다. 즉, RoB tool은 연구가 실제로 수행된 것을 전제로 하는데 (대상이 연구 결과이다), INSPECT-SR은 연구가 실제로 수행된 것인지, 보고된 데이터가 진실한 것인지, 그 전제에 의문을 던지는 도구 (대상이 연구 자체이다)이다. 이는 특히 오늘날 증가하고 있는 연구 부정행위나 데이터 위조에 대응하기 위해 개발된 도구라 할 수 있겠다.
워크샵이 끝난 뒤, 사용자들의 피드백을 언제든지 받는다고 하여, 이 평가도구는 연구 수행에 있어서 여러 측면의 전문성을 필요로 하는 도구로 보이므로, 평가도구를 사용한 사람의 전문성을 기재하도록 하고, 평가한 일시도 기재하도록 하는 것이 어떨까? 하는 이메일을 이 워크샵을 진행한 Jack Wilkinson 박사에게 보냈다. 도구의 최종 버전에 이 내용이 반영될지 안 될지는 모르겠으나, 이런 교류도 국제학술대회의 묘미가 아닐까 싶다.
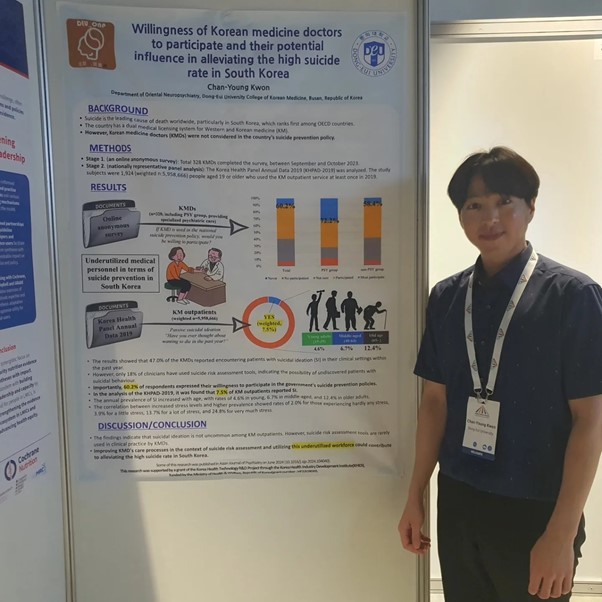
필자는 이번 학술대회에서 그 동안 진행해왔던 한국의 높은 자살률 문제에서 한의사의 역할을 포스터로 발표했다. 사실 이 연구는 한의사 대상 설문조사와 한국의료패널 분석 결과를 기반으로 한 것이라, 체계적 문헌고찰에 주로 관심이 있을 것으로 생각되는 이 학술대회 참가자들의 흥미는 끌지 못하지 않을까? 라는 걱정을 했지만, 의외로 자살이라는 키워드가 특히 유럽 쪽 연구자들의 관심을 끌어서 여러 연구자들과 이 연구 결과에 대해 얘기할 기회를 가질 수 있었다.
한국의 자살률이 그렇게 높은지 몰랐다며, 흥미로운 주제의 연구라고 했던 Cochrane Denmark의 연구자. 덴마크의 행복 추구 문화가 부럽다고 얘기를 나눴다.
최신 동향이 한의학에 주는 시사점
이번에 참여한 Global Evidence Summit 2024는 근거기반의학의 현재와 미래를 조망할 수 있는 귀중한 기회였다. 특히 AI와 머신러닝 기술의 도입이 체계적 문헌고찰, 메타분석, 임상진료지침 개발 등 다양한 영역에서 혁신을 가져오고 있음을 확인할 수 있었다. 또, 동시에 이러한 새로운 기술과 방법론의 정확성, 신뢰성, 윤리적 측면에 대한 지속적인 평가와 논의가 필요하다는 점도 강조되고 있었다. 하지만 결국 이 흐름은 불가피하며, 앞으로 10년, 5년 정도 후에는 AI가 의료 의사결정을 위한 중요 연구의 방법론이나 임상진료지침의 개발 및 평가에 깊숙이 들어와 있을 것이라는 생각이 들었다.
또, 체계적 문헌고찰과 메타분석 방법론은 계속 발전하고 있으며, 개별 연구에 대한 평가에서도 새로운 방법론과 도구들이 제안되고 있어, 향후 더욱 체계적이고 효율적인 근거기반 의사결정이 가능해질 것으로 기대된다. 그리고 이러한 최신 동향은 결국 한국 한의학 분야의 근거기반 실무 발전에도 중요한 시사점을 제공할 것이라 생각한다.
 속초21.5℃
속초21.5℃ 22.8℃
22.8℃ 대관령23.8℃
대관령23.8℃









![[자막뉴스] 한의약·젊음·음악이 한데 어우러진 시간](https://akomnews.com/data/photo/2606/990852453_QhlSFKyT_e5dcceb839666f8c85ca577024f091a1038ddb44.jpg)
![[자막뉴스] 한의협-국방부, 군관계자 대상 한의의료 지원 협약 체결](https://akomnews.com/data/photo/2606/990852453_5MTtEXWL_38dad69618c034483901604775219f4fffc9ada7.jpg)
![[자막뉴스] 범한의계 일차의료 총력대응위 출범 “재택의료·통합돌봄 한의 역할 확대”](https://akomnews.com/data/photo/2606/990852453_LAr76vKw_2748dc5af2663d9aad0e8776a489fddfdd33f1c9.jpg)
![[자막뉴스] 지방선거, 한의계 정책전 한의협, 지역 맞춤형 공약 제안](https://akomnews.com/data/photo/2605/990852453_uxarP7Wj_8fcef50c89a804cbfb1a9b3490aa3b6687d7be33.jpg)