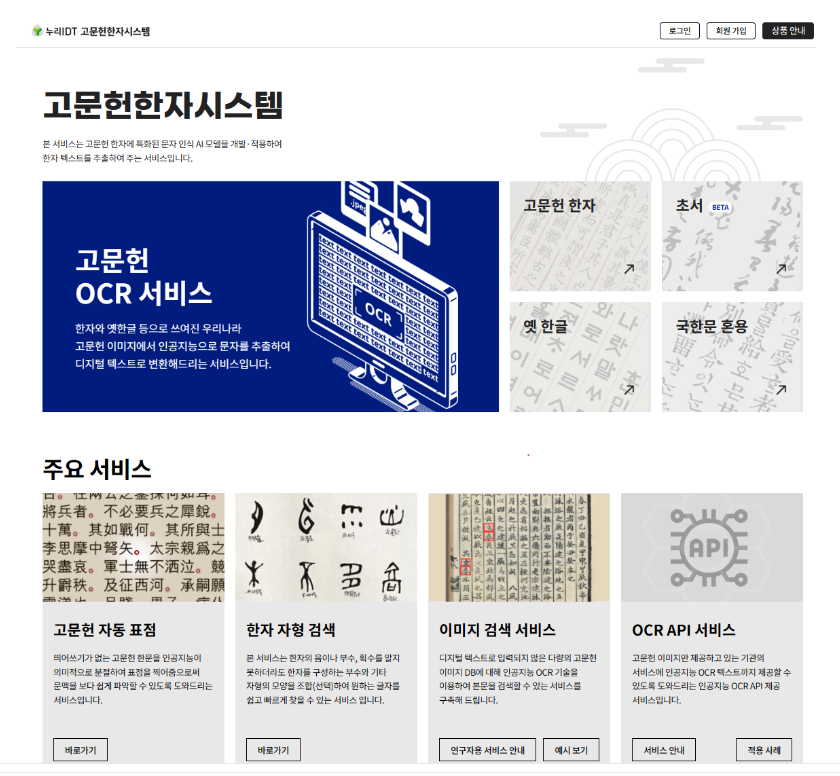
[한의신문] 지능형 데이터 전문 기업 (주)누리아이디티(대표 배성진)는 인공지능(AI) 기술을 기반으로 초서체 한자와 옛 한글, 국한문 혼용문을 자동 인식하는 <고문헌 OCR 서비스> 3종과 고문헌 원문 한문을 띄어쓰기해 주는 <자동 표점 서비스>를 출시했다고 3일 밝혔다.
누리IDT는 지난해 5월 AI 모델이 고문헌의 해서체와 행서체 한자를 평균 98%의 정확도로 자동 인식하여 디지털 텍스트로 변환해 주는 <고성능 한자 OCR 서비스>를 개발하여 언론과 학계의 호평을 받은 바 있다.
AI 기반 초서, 옛 한글, 국한문 혼용 등 고문헌 OCR 3종 추가 개발
이번에 흘려쓴 손글씨인 초서체 한자를 AI가 인식하여 정자(正字)로 자동 변환해 주는 <초서 OCR>, 한글 고문헌을 읽어주는 <옛 한글 OCR>, 한자와 한글이 혼용된 고문헌 문서를 읽어주는 <국한문 혼용 OCR> 등 3종의 AI 기반 OCR 모델을 새로 개발해 기존 해서/행서체 고문헌 한자 OCR 서비스에 추가해 출시한 것이다.
이에 따라 대부분 원문 이미지 아카이브 형태로 구축되어 있는 국내 고문헌 자료를 간편하고 효율적으로 디지털 텍스트로 변환해 활용하거나 데이터베이스로 구축할 수 있게 됐다.
특히 <초서 OCR>은 난해한 초서 글자를 AI 모델이 자동 인식하여 정자로 바꿔 준다는 점에서 이 서비스의 출시 이전부터 사용자들의 주목과 기대를 받아 왔다. 손글씨로 흘려쓴 초서 필사본은 <승정원일기>와 같은 국가 공식 기록물을 비롯해 각종 공문서, 개인 문집, 일기류, 서한 등 전통 고문헌의 상당 부분을 차지하고 있지만 소수의 초서 전문가들이 일일이 탈초(정자로 옮겨쓰기)해 주기 전에는 고문헌 연구자들도 판독하기 어려워하는 대상이었다.
하지만 이번 프로그램 개발에 따라 초서 원문을 본 <초서 OCR> 서비스를 이용해 연구자들을 포함해 누구나 좀 더 쉽고 간편하게 읽고 디지털 텍스트로 활용할 수 있게 됐다. 다만 초서 자료는 워낙 유형이 다양한 까닭에 OCR 인식률을 크게 높이기 어려운 한계가 있다.
누리IDT는 AI 모델 알고리즘의 개선 및 보다 많은 초서 학습 데이터의 확보를 통해 OCR 성능을 지속적으로 향상시켜 나갈 예정이다.
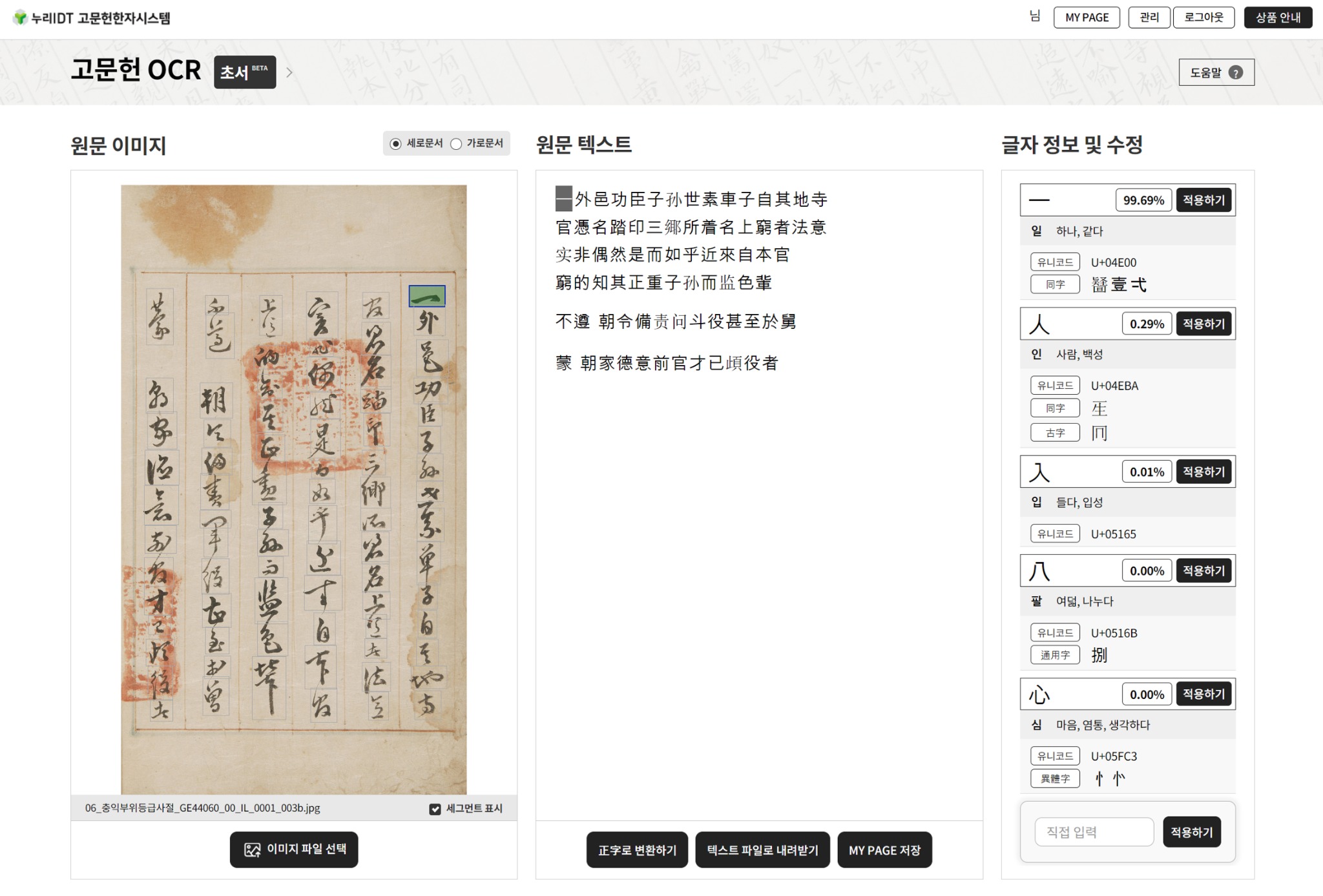
<초서 OCR 서비스>의 초서 원문 이미지 자동 인식과 텍스트 출력
국내 기업 최초로 고성능 고문헌 한문 자동 표점 프로그램 개발, 서비스 공개
누리IDT는 이 신규 <고문헌 OCR 서비스>와 함께 고문헌 원문 한문의 <자동 표점 서비스>도 새로 개발해 출시했다. 표점이란 원문 전체가 하나의 문장처럼 붙여쓰여 작성된 고전 한문 텍스트에 대해 의미 단위로 띄어쓰기하고 온점(。마침표)과 반점(, 쉼표) 등 구두점을 찍어 문장을 구분하는 것을 말한다.
이러한 표점 작업은 한문 원문을 정확하게 해석하거나 현대어로 번역하자면 반드시 선행돼야 하는 과정으로, 지금까지는 전문 연구자들이 원문 텍스트 한 줄 한 줄에 대해 꼼꼼히 읽고 의미 단위마다 일일이 구두점을 찍는 고된 작업을 해 왔다. 대표적으로 표점과 번역에 20년 이상이 걸린 <조선왕조실록>, 완료하기까지 앞으로도 40년 이상이 더 소요될 <승정원일기> 번역 사업 등이 그렇게 진행되고 있다.
누리IDT의 고성능 <자동 표점 서비스>는 전문가들만이 할 수 있는 고되고 오랜 시간 걸리는 표점 작업을 AI가 자동으로 순식간에, 매우 정확하게 처리해 준다. 누리IDT는 이를 위해 트랜스포머 계열의 최신 자연어처리(NLP) 모델로 1억 자 이상의 한문 데이터를 학습시킨 자동 표점 AI 모델을 개발하여 웹서비스로 공개했다.
1,000자 분량의 한문 원문 텍스트를 붙여 넣거나 파일 불러오기로 입력하면 1초 이내에 표점을 처리해 주며, 표점의 정확도는 90% 이상으로서 관련 전공 석사 수준을 능가하는 고성능을 시현한다. 표점이 잘못 처리된 경우에는 사용자가 결과 화면에서 곧바로 수정 입력할 수 있는 기능도 제공하므로 이 서비스를 이용하면 전문가가 한 달 넘게 전념해야 할 표점 작업을 단 하루 만에 마칠 수가 있다.
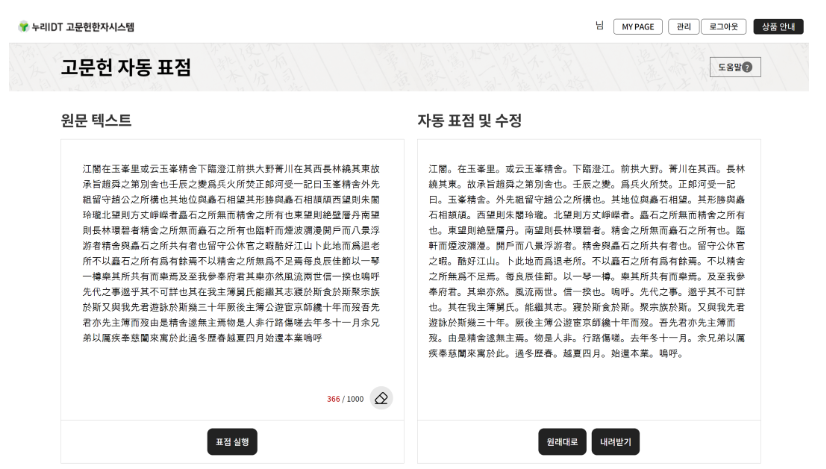
<고문헌 자동 표점 서비스>의 원문 텍스트 입력과 자동 표점 텍스트 출력
고문헌 문자 인식 – 자동 표점 – 자동 번역을 목표로 하는 고문헌 토털 솔루션
우리나라의 고문헌 자료는 문화 콘텐츠의 보고로 알려져 있지만 300만 점 이상으로 추산되는 국내 고문헌 자료는 약 50% 정도가 디지털 원문 이미지만 구축되어 있을 뿐이고 원문의 텍스트화는 5% 수준을 밑돌고 있다. 고문헌 자료가 문화 콘텐츠로서 널리 활용되기 위해서는 원문이 디지털 텍스트로 전환되어 검색과 공유가 용이해져야 하며, 원문 텍스트가 현대어로 번역되어 누구나 쉽게 접근하고 읽을 수 있어야 한다.
누리IDT의 <고문헌한자시스템>은 고문헌 자료의 자동 문자인식 ▷자동 표점 ▷자동 번역의 자동 처리 토털 솔루션을 목표로 하는 서비스이다.
<고문헌 OCR> 3종과 <자동 표점 서비스>를 신규 출시하면서 누리IDT의 배성진 대표는 “작년에 <고문헌 한자 OCR>을 출시한 이후 지속적인 투자로 고문헌 토털 솔루션의 두 번째 단계에 도달하게 됐다”면서 “이번에 새롭개 공개한 OCR과 표점 서비스가 고문헌 자료의 텍스트화와 활용에 적극 사용되기를 바란다”고 밝혔다.
=누리IDT 고문헌한자시스템 바로가기(https://ocr.nuriidt.co.kr/)
 속초20.0℃
속초20.0℃ 22.1℃
22.1℃









![[자막뉴스] 한의약·젊음·음악이 한데 어우러진 시간](https://akomnews.com/data/photo/2606/990852453_QhlSFKyT_e5dcceb839666f8c85ca577024f091a1038ddb44.jpg)
![[자막뉴스] 한의협-국방부, 군관계자 대상 한의의료 지원 협약 체결](https://akomnews.com/data/photo/2606/990852453_5MTtEXWL_38dad69618c034483901604775219f4fffc9ada7.jpg)
![[자막뉴스] 범한의계 일차의료 총력대응위 출범 “재택의료·통합돌봄 한의 역할 확대”](https://akomnews.com/data/photo/2606/990852453_LAr76vKw_2748dc5af2663d9aad0e8776a489fddfdd33f1c9.jpg)
![[자막뉴스] 지방선거, 한의계 정책전 한의협, 지역 맞춤형 공약 제안](https://akomnews.com/data/photo/2605/990852453_uxarP7Wj_8fcef50c89a804cbfb1a9b3490aa3b6687d7be33.jpg)